The Role of Tokens for GPT Models
Understanding Tokens in OpenAI APIs
When working with any of the OpenAI APIs, one of the most important concepts to understand is tokens.
GPT models don't work with words as we know them in the English language, but instead break things down into a system of tokens which are usually pieces of words, although some tokens are actually full words.
On average, a token is about four characters of English text (it does vary from language to language).

As an example, the phrase "I like hamburgers" is three English words but it's actually five separate tokens in the world of GPT.
Pricing and API Request Cost
Tokens determine billing and how much our API requests cost.
OpenAI charges based on the number of tokens that we use, both in the prompt plus the tokens in the output. They multiply the number of tokens by the price per token, which varies from one model to the next.
As of this writing, there are some very cheap models, along with the comparatively expensive GPT-4.

Although for GPT-4, there's two different price points, and I'll talk about why in a moment. If you look at GPT-3.5 Turbo, it is significantly cheaper, $0.002 for 1,000 tokens.
Tokenizer Tool
There's a tool called the Tokenizer on the OpenAI website.
While the tool does not support GPT-4 or 3.5, it will show us the tokens behind the scenes.
Let's look at the phrase "hello world my name is colt":
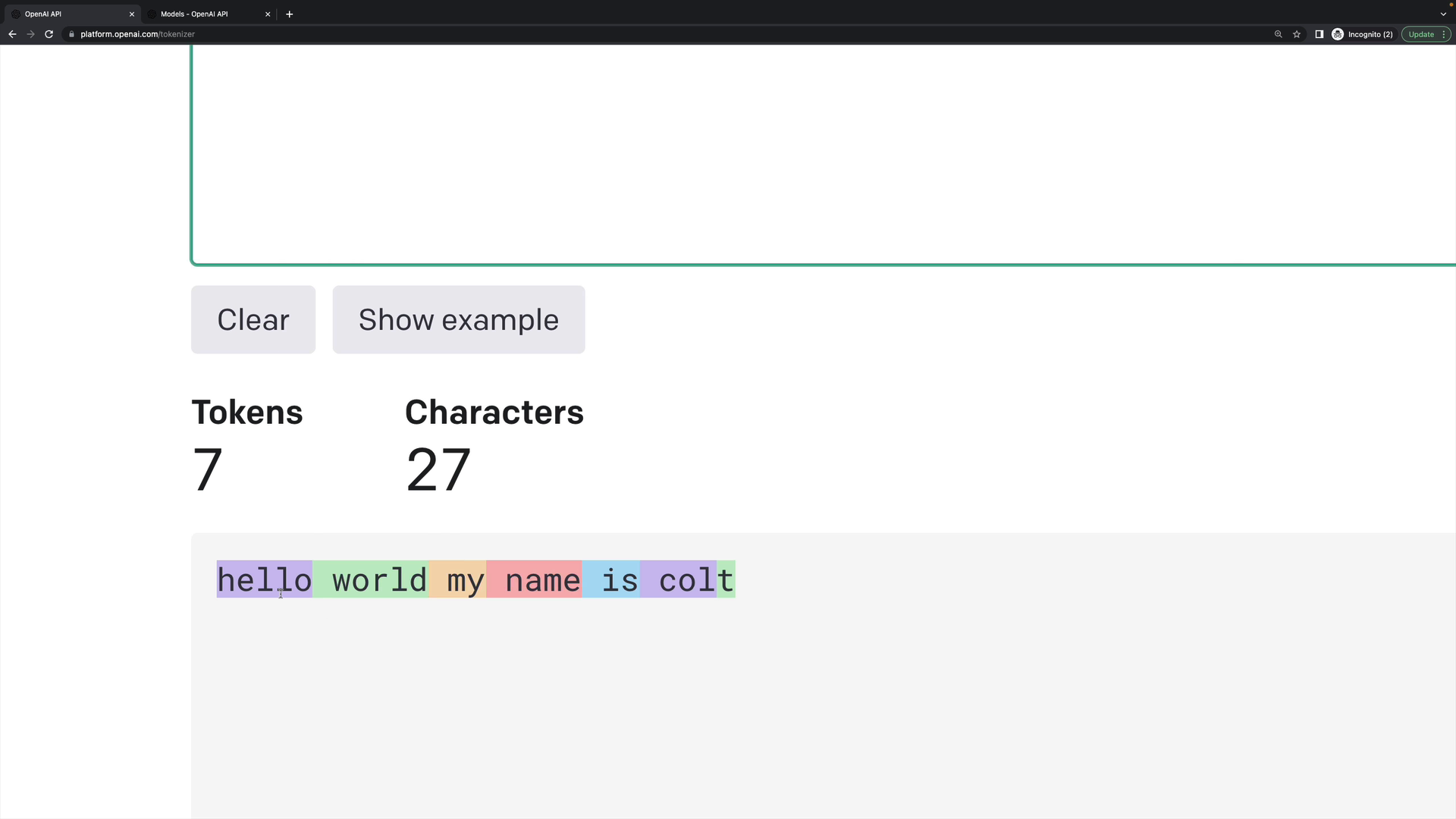
You can see some of these tokens are full words, and they often will have a leading space. But then something like "col" isn't really a word, and the final letter "T" is its own individual token.
We would be billed seven tokens for this individual phrase.
Token Usage Example
Here is an example of simple sentiment analysis request in Python. The prompt was a list of messages, and the sentiment output it gave was the word "neutral."
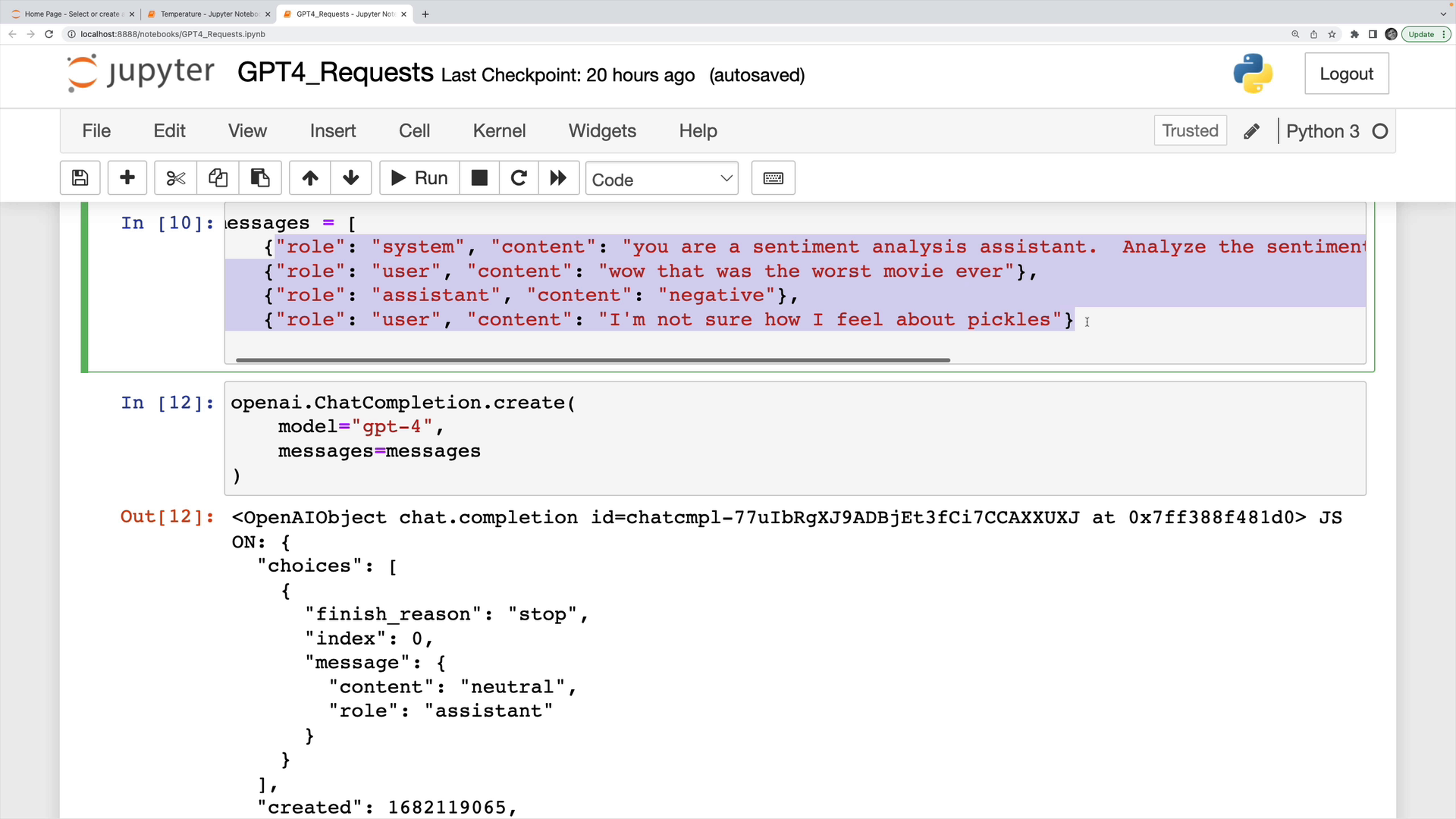
Looking at the usage portion of the response, we can see the total number of tokens used.
In this case, the number of tokens in the completion (output) was one token. The number of tokens in the prompt was 59 tokens, so our total was 60 tokens.
In this example the request used GPT-4, so I would be billed for 60 tokens at the rate of six cents per 1,000 tokens (at the time of this writing).
Maximum Context Window
The other reason tokens really matter is that there is a maximum context window for each model. This is the total number of tokens that each model can work with at a given time.
For the base gpt-4, that number is 8,192 tokens. However there are different variations like gpt-4-32k that have a maximum of 32,768 tokens, though it comes at double the price.
This context window is not just the length of the input, but the maximum number of tokens the model can work with period. It's the input plus the output tokens.
Generally token limits are not a problem for smaller tasks, though larger tasks like summarizing a book or really long chat conversations may give you problems when you run out of tokens.
It's a good idea to be aware of the amount of tokens you use!
Transcript
00:00 If you're working with any of the OpenAI APIs, one of the most important concepts to understand is tokens. So the GPT models don't work with words as we know them in the English language, but instead break things down into a system of tokens, which are basically pieces of words, although some tokens are actually full words.
00:19 On average, a token is about four characters of English text. Again, that's in English, it does vary from language to language. So as an example, the phrase, I like hamburgers, is three English words, but it's actually five separate tokens in the world of GPT. So there's two main reasons this matters.
00:38 One is for billing and how much our API requests cost. OpenAI will charge us based on the number of tokens that we use, both in the prompt plus the tokens in the output. So it adds them together, and then it multiplies the number of tokens by the price per token, which varies from one model to the next.
00:56 So there's some very cheap models, and then there's a very expensive model, which is GPT-4. Although for GPT-4, there's two different price points, and I'll talk about why in a moment. If you look at GPT-3.5 Turbo, it is significantly cheaper, $2.002 for 1,000 tokens.
01:14 So there's a tool called the Tokenizer on the OpenAI website. It does not support GPT-4 or 3.5. But if we type things in here like, hello world, my name is Colt, it will show us the tokens behind the scenes. You can see some of these tokens are full words,
01:34 and they often will have a leading space. But then something like this right here, Colt isn't really a word anyway, but the final letter T is its own individual token. We would be billed seven tokens for this individual phrase. When we make a request, like this one I'm making in Python, a simple sentiment analysis request.
01:53 This is my prompt, a list of messages. This is the output it gave me, the word neutral. It assessed the sentiment was neutral in the tweet that I provided. But if we look at the usage portion of the response, it tells us the number of tokens in the completion, that's the output, was one token. So this was one token.
02:12 The number of tokens in the prompt was 59 tokens. So all of this was 59 tokens. Then the total tokens is the sum of the two, 60 tokens. I was using GPT-4. So I would be billed at six cents per 1,000 tokens, and I used 60 tokens. Now, the other reason tokens really matter is that there is
02:30 a maximum context window, a maximum number of tokens that each model can work with at a given time. So for GPT-4, that number is 8,192 tokens. Although there is a much larger context window available, if you use a different variation,
02:47 GPT-4 32K, this is way more expensive. That's the 12 cents per 1,000 tokens compared to the six cents for 1,000 tokens. So this context window is not just the length of the input, but it's actually the maximum number of tokens the model can work with period. It's the input plus the output tokens.
03:06 If we look at other models like 3.5 Turbo, 4,096 tokens is its context window. Generally, for a lot of the prompts that I write, it's not a problem. But if I'm trying to summarize a book or have a really long chat conversation, you can start to run out of tokens, and that can be a big problem. So in a separate video,
03:24 I'll cover different ways of counting
03:26 tokens programmatically using a library called TickToken.